
Dr hab. Barbara Pękala, prof. WSIZ
Profesor w Wyższej Szkole Informatyki i Zarządzania oraz na Uniwersytecie Rzeszowskim. Jej zainteresowania badawcze koncentrują się na eksploracji i stosowaniu rozszerzeń teorii zbiorów rozmytych, np. funkcji agregujących, czy miar uwzględniających niepewność i nieprecyzyjność w metodach inteligencji obliczeniowej, takich jak wnioskowanie przybliżone, eksploracja danych, czy uczenie federacyjne. Aktywnie wspiera działalność stowarzyszeń naukowych poprzez pełnienie funkcji: prezesa Polskiego Towarzystwa Zbiorów Rozmytych (POLFUZZ), wiceprezesa EUSFLAT oraz członka Komitetu Technicznego Systemów Rozmytych (FSTC) CIS.
Trendy i wyzwania związane z uczeniem federacyjnym
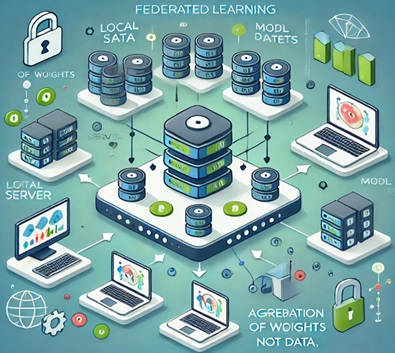
Uczenie federacyjne (ang. Federated Learning, FL) to technika uczenia maszynowego, w której model trenowany jest w sposób rozproszony, przy wykorzystaniu danych zgromadzonych lokalnie na urządzeniach końcowych, takich jak smartfony, komputery czy serwery w różnych lokalizacjach. Dzięki temu podejściu dane użytkowników nie opuszczają ich urządzeń, co zwiększa ich prywatność i bezpieczeństwo.
Uczenie federacyjne działa poprzez iteracyjne aktualizowanie globalnego modelu na podstawie lokalnych aktualizacji z urządzeń, które przetwarzają swoje dane lokalnie.
Główne zalety tego podejścia to:
- Prywatność danych: dane nie są centralnie przechowywane ani przesyłane do serwera.
- Redukcja kosztów przesyłania danych: tylko wagi modelu są przesyłane między serwerem a urządzeniami.
- Skalowalność: dzięki rozproszeniu obliczeń na wiele urządzeń.
Projekt dr hab. Barbary Pękali, prof. WSIiZ, stworzony przy użyciu AI
Uczenie federacyjne zostało po raz pierwszy zaproponowane przez badaczy z Google w 2016 roku. Koncepcja FL była odpowiedzią na rosnące potrzeby ochrony prywatności i bezpieczeństwa danych, zwłaszcza w kontekście urządzeń mobilnych, takich jak smartfony, gdyż pierwszym praktycznym przykładem zastosowania FL była klawiatura Google Keyboard (obecnie Gboard), która wykorzystywała uczenie federacyjne do usprawnienia predykcji tekstu i autokorekty, trenując modele na danych lokalnych użytkowników.
Metoda FL zdobywa coraz większą popularność, szczególnie w kontekście ochrony prywatności i przetwarzania danych na dużą skalę. Poniżej omówiono najważniejsze trendy i wyzwania związane z uczeniem federacyjnym.
Trendy w uczeniu federacyjnym
W związku z potencjałem i korzyściami płynącymi z wykorzystywania techniki FL możemy zaobserwować następujące kierunki jej rozwoju:
- Ochrona prywatności i bezpieczeństwo danych
Uczenie federacyjne znajduje zastosowanie w aplikacjach wymagających ochrony danych, takich jak opieka zdrowotna, finanse czy aplikacje mobilne (np. personalizowane sugestie na smartfonach). Dzięki temu firmy mogą korzystać z danych użytkowników bez ich centralnego gromadzenia. - Integracja z IoT (Internet of Things)
Urządzenia IoT generują ogromne ilości danych, a uczenie federacyjne pozwala na lokalne przetwarzanie tych danych, co zmniejsza koszty przesyłu i zapewnia lepszą ochronę prywatności. - Optymalizacja energetyczna i obliczeniowa
Wykorzystanie uczenia federacyjnego w urządzeniach o ograniczonych zasobach (np. smartfony, sensory IoT) prowadzi do rozwoju bardziej efektywnych algorytmów optymalizujących zużycie energii i pamięci. - Zastosowanie w aplikacjach mobilnych i personalizacji
FL jest coraz częściej stosowane przez firmy technologiczne, takie jak Google (np. w Gboard) czy Apple, w celu poprawy personalizacji usług bez narażania prywatności użytkowników. - Rozwój algorytmów tolerujących błędy
Postępy w projektowaniu algorytmów odpornych na różnorodność danych (ang. non-IID data) i nierównomierny rozkład danych między uczestnikami systemu zwiększają możliwości FL.
Wyzwania związane z uczeniem federacyjnym
Rozwój techniki FL bezpośrednio związany jest z wyzwaniami jakie stawia przed FL współczesny rozwój cywilizacyjny, gdzie obok efektywności systemów decyzyjnych, równie ważne jest bezpieczeństwo danych. Zatem możemy wyróżnić następujące wyzwania stawiane przed FL:
- Heterogeniczność danych i urządzeń
Dane na różnych urządzeniach mogą być bardzo różnorodne (ang. non-IID), co utrudnia efektywne trenowanie modeli. Dodatkowo urządzenia różnią się pod względem mocy obliczeniowej, pamięci i dostępności sieci. - Zabezpieczenia przed atakami
Chociaż dane nie są przesyłane w formie surowej, FL jest podatne na ataki, takie jak ataki złośliwych uczestników (ang. poisoning attacks) czy ataki rekonstrukcji danych. - Efektywność komunikacji
FL wymaga wielu iteracji wymiany parametrów między urządzeniami a serwerem centralnym. To generuje duże koszty komunikacyjne, szczególnie w systemach o ograniczonych przepustowościach. - Brak standaryzacji i interoperacyjności
Obecnie brakuje standardów w implementacji FL, co utrudnia jego skalowanie i integrację w różnych środowiskach. - Regulacje prawne
Uczenie federacyjne wiąże się z koniecznością zgodności z lokalnymi i międzynarodowymi regulacjami dotyczącymi ochrony danych, takimi jak RODO w Unii Europejskiej czy CCPA w Kalifornii. - Złożoność algorytmiczna
Projektowanie algorytmów, które są jednocześnie wydajne, skalowalne i odporne na różnorodność danych, pozostaje wyzwaniem badawczym.
Uczenie federacyjne otwiera nowe możliwości w zakresie ochrony prywatności i wykorzystania danych w sposób zdecentralizowany. Mimo to wymaga rozwiązania licznych wyzwań technicznych i organizacyjnych, takich jak heterogeniczność danych, bezpieczeństwo czy ograniczenia infrastrukturalne. Trendy wskazują na dynamiczny rozwój tej dziedziny, a współpraca między środowiskiem akademickim, przemysłem i regulatorami jest kluczowa dla pełnego wykorzystania jej potencjału.
Wśród najważniejszych przykładów zastosowań uczenia federacyjnego możemy wyróżnić:
- Personalizacja aplikacji mobilnych:
– Autokorekta i przewidywanie słów w klawiaturach (np. Gboard).
– Rekomendacje treści w mediach społecznościowych. - Opieka zdrowotna:
– Analiza danych medycznych bez udostępniania wrażliwych informacji.
– Tworzenie modeli predykcyjnych na podstawie danych z różnych szpitali. - Finanse:
– Wykrywanie oszustw w systemach płatniczych z zachowaniem poufności danych transakcyjnych.
Dziś uczenie federacyjne jest kluczowym podejściem w dziedzinach wymagających ochrony danych, takich jak zdrowie, finanse, IoT i telekomunikacja. Wraz z postępem w dziedzinie sztucznej inteligencji oraz wzrostem regulacji dotyczących prywatności (np. RODO, HIPAA), FL zyskuje coraz większe znaczenie jako rozwiązanie umożliwiające trenowanie modeli AI w sposób etyczny i efektywny.
