
Adiunkt w Katedrze Mediów i Dziennikarstwa i Komunikacji Społecznej. Autor szeregu publikacji i książek o kulturze cyfrowej. Tłumacz, wydawca i producent literatury cyfrowej. Założyciel pisma “Techsty. Literatura i nowe media”. Uczestniczy w międzynarodowych laboratoriach i projektach w USA (Washington State University, Vancouver) i na Słowacji (Słowacka Akademia Nauk, Uniwersytet Cyryla i Metodego w Trnawie). Czas wolny spędza wśród starych komputerów Macintosh, gitar elektrycznych, oraz na leśnych i górskich szlakach.
Jak badać media społecznościowe? Historia jednego hasztagu
„Media społecznościowe, zamieniając każdego z nas w autonomiczny kanał informacyjny o potencjalnie milionowej publiczności, potrafią wygenerować wiadomościowe piekiełko. Na szczęście te same media dają nam w ręce narzędzia, dzięki którym możemy odkryć stojącą za informacją sieć powiązań.”
W świecie, w którym wiadomości, komentarze i refleksje na temat bieżących wydarzeń do wielu z nas trafiają najpierw poprzez media społecznościowe, a dopiero później poprzez radio, telewizję i prasę, nie sposób oddzielić informacyjnego ziarna od plew. Jeszcze trudniej odczytać intencję kogoś, od kogo informacja wychodzi. Polaryzacja, spadek zaufania do nauki, faktów i statystyk, wzrost wiary w teorie spiskowe i domorosłych autorytetów – to skutki niehierarchicznej dystrybucji wiadomości właściwej dla Facebooka, Instagramu i Twittera. Media społecznościowe, zamieniając każdego z nas w autonomiczny kanał informacyjny o potencjalnie milionowej publiczności, potrafią wygenerować prawdziwe wiadomościowe piekiełko. Na szczęście te same media dają nam w ręce narzędzia, dzięki którym możemy zobaczyć stojącą za informacją sieć powiązań: klarownie oddzielić wpływowego komentatora od trolla, odróżnić fakty od informacyjnego znachorstwa. Chodzi o tak zwane badania jakościowe sieci (ang. qualitative data analysis), które za sprawą coraz prostszych w obsłudze programów oferują sprawną, przyjazną dla każdego humanisty, dziennikarza, a nawet dociekliwego amatora, analizę i wizualizację przepływu informacji.
Jak możemy badać media społecznościowe?
Programy takie jak Gephi, Tags i Netlytic umożliwiają zebranie hurtowej ilości wpisów na Twitterze (Facebook od dawna przestał oferować narzędzia analityczne szerszej publiczności), a następnie ich wizualizację i obróbkę. Wystarczy podać hasło, bądź hasztag, najlepiej w kilku wariantach gramatycznych, aby po kilku sekundach dysponować bazą kilku tysięcy wpisów na interesujący nas temat z całą paletą metadanych o liczbie wzmianek, retweetów i lajków, które każdy z postów generuje. Po kilku dniach nasza baza rozrosnąć się może wielokrotnie. Jaki z tych danych pożytek? Otóż wymienione programy niemalże w locie wytwarzają interaktywne mapy społecznościowej sieci. Jej węzły to uczestnicy dyskusji, natomiast linki łączące te węzły to bezpośrednia liczba postów między sobą. Mapy sieci rozrysowują ranking najczęściej cytowanych postów i najbardziej aktywnych uczestników dyskusji . Pozwala to na błyskawiczne wizualne prześledzenie “dziejów” pojedynczego hasztagu i jego komentatorów: na mapach sieci społecznościowej widać jak na dłoni, że jeden tweet osoby o wysokim publicznym statusie jest wart dużo więcej niż dwadzieścia tweetów bezmyślnego hejtera lub trolla. Ci ostatni nie posiadając dużej publiczności obserwujących wytwarzają jedynie szum, który najczęściej nie znajduje posłuchu.

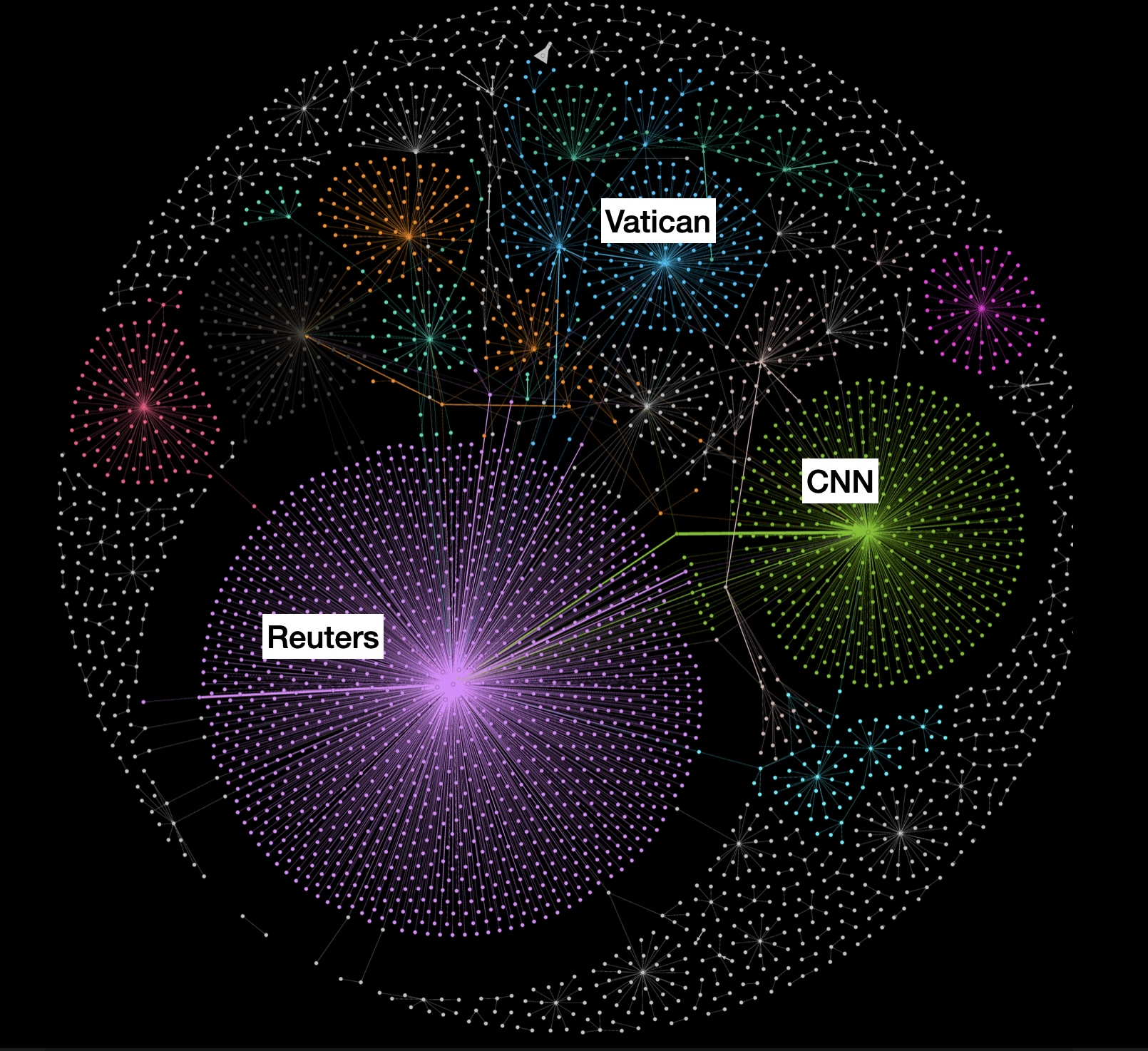
Ilustracja 1
Ilustracja 1. Dystrybucja noworocznego przesłania Urbi et Orbi Papieża w Twittersferze w programie Netlytic (https://netlytic.org). Widoczne są wyraźne kręgi nadawców i odbiorców, oraz wspólne punkty łączące media katolickie z mediami świeckimi. Więzi Watykanu z CNN okazuję się dużo mocniejsze niż z agencją Reuters i jej odbiorcami.
Olga Tokarczuk i szczepienia
Najcenniejszym narzędziem sieciowej wizualizacji są wbudowane w Gephi, Tags i Netlytic algorytmy wykrywania społeczności (ang. community detection algorithms). Mierząc stopień pokrewieństwa między węzłami i dystans miedzy nimi segregują one uczestników dyskusji w bliskie sobie ideologicznie i światopoglądowo grupy. Obserwując hasztagi #zwróćoldzeksiążkę czy #odszczepsię mogłem zobaczyć, które z informacyjnych portali ze szczególnym naciskiem nakłaniają swoich czytelników do bojkotu polskiej Noblistki, jak duże są koła adoracji rzeczonych idei, a także prześledzić fascynujące powiązania między grupami zwolennikami i przeciwników. Ostatecznie żyjemy bowiem w jednym społeczeństwie i łączy nas dużo więcej niż poglądy.
Wizualizacja dyskusji na Twitterze dostarcza nam nowej formy tradycyjnej lektury prasy, czyli “prasówki”. Zamiast jednak, co było regułą, obierać tę samą informację z co najmniej dwóch źródeł i dwóch punktów widzenia, korzystamy z tysięcy żródeł. Ale ostatecznie, gdy algorytmy podzielą owe tysiące na społeczności, i tak zostajemy z kilkoma źródłami oraz z jedną, i jak się okazuje niezniszczalną, zasadą. Nie zależnie od tego, jak dużo i jak głośno coś się ogłasza (mythos), swą wiarygodność i status buduje się latami (ethos). To dobre wieści dla tych, którzy boją się o przyszłość rzetelnej informacji. Prasówka oparta na BIG DATA jest w stanie odcedzić internetowych troli, eksponować hejterów i demaskować źródła fake newsów.
Ilustracja 2. Graf Fruchtermana-Reingolda
