
Asystent w katedrze Zastosowań Systemów Informatycznych Wyższej Szkoły Informatyki i Zarządzania w Rzeszowie, absolwent WSIiZ. Ukończył studia magisterskie o specjalności Inżynieria Produkcji Oprogramowania. Aktywny zawodowo od 2008 roku. Pracował w wielu firmach lokalnych oraz zagranicznych jako grafik, ilustrator i programista. Długotrwale związany z branżą gier wideo. Pracował dla spółek produkujących gry klasy AAA. Od 2017 roku prowadził własną działalność gospodarczą pod nazwą SYNOISE.
Zastosowanie sztucznej inteligencji w komponowaniu i tworzeniu muzyki
Szybki rozwój w dziedzinie uczenia maszynowego (Machine Learning) wpływa na przemysł i nasze życie codzienne. Rewolucja ta ma znaczny wpływ także na sferę kulturową i artystyczną.
Usługa Midjourney umożliwia szybkie generowanie ilustracji w wysokiej jakości, na podstawie informacji podanych przez użytkownika. Jest ona często krytykowana przez ilustratorów i artystów. Twierdzą oni, że narusza ona prawa autorskie, modyfikując obrazy, które nie należą do twórców tego rozwiązania. Warto pamiętać, że podobne metody kopiowania czy wzorowania się, stosowane są wśród początkujących artystów (np. kalkowanie czy używanie pantografu), co spotyka się z podobnymi zarzutami. A jak wygląda udział sztucznej inteligencji w komponowaniu i tworzeniu muzyki?
„Drowned In The Sun” czyli Nirvana, AI I zespół … z Rzeszowa!
Jedną z pierwszych potrzeb w branży IT związanej z wykorzystaniem sygnału dźwiękowego była synteza mowy (Text-To-Speech). Wiele patentów w tej dziedzinie powstało już dawno, a komputery PC posiadają standardowo wsparcie sprzętowe do syntezy dźwięku. Rozwój sieci neuronowych pozwala obecnie w tej dziedzinie na realizację bardziej złożonych problemów, takich jak: wirtualne komponowanie utworów, stworzenie wirtualnego muzyka-improwizatora, a także usprawnienie procesu twórczego artysty.
W 2020 roku pojawił się utwór muzyczny „Drowned In The Sun”, stworzony przez sztuczną inteligencję. Przedstawia on alternatywne brzmienie zespołu Nirvana w obecnych czasach. Ciekawym jest to, że melodycznie i brzmieniowo przypomina utwór „Biała Chorągiewka” zespołu 1984. Może to świadczyć o tym, że przy generowaniu, tego utworu, została użyta wzorcowa baza utworów muzycznych (dane trenujące). Nie są znane dokładne szczegóły techniczne, dotyczące procesu tworzenia utworu „Drowned In The Sun”, jednak istnieje kilka podejść wykorzystania algorytmów sztucznej inteligencji w muzycznym procesie twórczym.
Jak maszyna tworzy muzykę?
Jednym ze sposobów na wygenerowanie utworu jest wykorzystanie sieci neuronowych o głębokiej strukturze (DNN) do tak zwanego uczenia głębokiego (DL). W procesie tym najczęściej stosowane są rekurencyjne sieci neuronowe (RNN) lub sieci typu transformer.
Innym podejściem jest wykorzystanie algorytmu genetycznego do ewolucyjnego projektowania muzyki. W tym przypadku zamiast nauczać sieć neuronową na podstawie danych, generuje się sekwencje muzyczne poprzez wybrane lub losowe modulacje. Następnie przeprowadzane są iteracje algorytmu genetycznego. Najlepiej oceniane sekwencje są selekcjonowane i krzyżowane, aby stworzyć jeszcze nowsze sekwencje. Proces ten jest powtarzany aż do uzyskania satysfakcjonującego rezultatu.
Popularne programy do generowania muzyki, które korzystają z wymienionych rozwiązań to:
Amper Music – platforma pozwalająca tworzenie muzyki na podstawie wybranego gatunku, tempa i analogicznych kryteriów. Stosowane algorytmy zmieniały się; początkowo były to VNS, czyli zmienny algorytm wyszukiwania sąsiedztwa w celu przekształcania istniejących szablonów w nowe brzmienia. Obecnie platforma wykorzystuje algorytmy uczenia głębokiego.
AIVA (Artificial Intelligence Virtual Artist) – program oparty na architekturach głębokiego uczenia, który oficjalnie przyczynił się do skomponowania kilku znanych przebojów (utwory w grze Pixelfield, X Ambassadors – „Not Easy”, AIVA – „He said”)?
Jukedeck – narzędzie do tworzenia muzyki na podstawie wyboru gatunku, tempa i nastroju. Witryna została użyta do stworzenia ponad 1 miliona utworów muzycznych. Firmy, które korzystały z tego programu to między innymi Coca-Cola oraz Google.
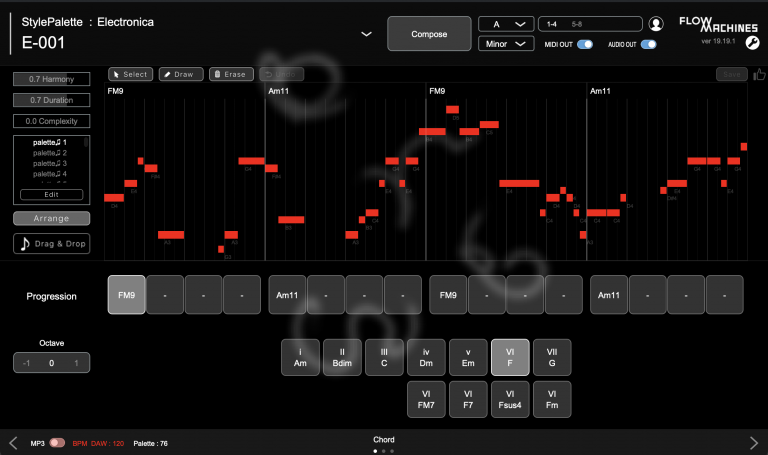
Widok programu Flow Machines (Sony)
Flow Machines (Sony) – wykorzystuje technikę nazywaną „style transfer”, która polega na nauczeniu sieci neuronowych różnych stylów muzycznych, a następnie na łączeniu ich w celu stworzenia nowych, oryginalnych utworów. Jest ona uważana za jedno z najbardziej innowacyjnych rozwiązań w dziedzinie automatycznego tworzenia muzyki. Wpływ tego produktu na przemysł muzyczny wciąż jest badany i analizowany.
WaveNet – to głęboka sieć neuronowa, stworzona przez naukowców z DeepMind. Technika umożliwia generowanie realistycznych dźwięków, które przypominają ludzką mowę, poprzez bezpośrednie modelowanie przebiegów fal z użyciem wytrenowanych modeli. Została wytrenowana na nagraniach prawdziwej mowy. System przewyższa najlepsze istniejące systemy zamiany tekstu na mowę (TTS). WaveNet potrafi generować każdy rodzaj dźwięku, w tym muzykę (pochodna wersja tego algorytmu mogła być użyte we wspomnianym utworze „Drowned In the Sun”).
DeepJ – to system opracowany przez zespół badawczy z Uniwersytetu Stanforda, który może generować muzykę na podstawie nastroju i emocji, opisywanych przez użytkownika. Jak sugeruje nazwa, stosuje głębokie sieci neuronowe. Więcej można dowiedzieć się TUTAJ.
Magenta – to projekt Google, wykorzystuje uczenie maszynowe w procesie komponowania muzyki. W jego ramach stworzono m.in. narzędzia do generowania melodii, harmonii i rytmów. Pluginy VST Magenta można pobrać ze strony TensorFlow, która tworzy zaawansowane biblioteki programistyczne do uczenia maszynowego. W ramach badań prowadzonych przez zespół Magenta udostępniono wiele narzędzi open-source, wytrenowanych modeli, oraz zbioru danych uczących (CocoChorales Dataset), które wspierają rozwój muzyki tworzonej maszynowo. Lista najciekawszych udostępnionych badań znajduje się TUTAJ.
Powyższe narzędzia pozwalają zminimalizować rolę muzyka – kompozytora w procesie twórczym, poprzez wsparcie sztucznej inteligencji. Efekt ich działania najczęściej stosowany jest w projektach komercyjnych, jak jingle reklamowe lub muzyka tła w grach, gdzie duże znaczenie mają czas i fundusze (a udział muzyka nie jest wymagany).
A co z muzyką rozrywkową?
W przypadku muzyki rozrywkowej, w której proces twórczy może sprawiać najwięcej satysfakcji, należy przyjrzeć się rozwiązaniom elementarnym, takim jak wirtualne instrumenty-VST (Virtual Studio Technology) opatentowane przez firmę Steinberg. Standard pluginów VST jest bardzo powszechny. Można używać ich jako generator dźwięku lub efekt modulacyjny w każdym programie muzycznym typu DAW (Digital Audio Workstation).
Znaczna część muzyki, której słuchamy, odtwarzana jest ze wzmacniacza cyfrowego i głośników. Efektem wyjściowym jest wektor liczb reprezentujący amplitudę sygnału dźwiękowego, zmieniającą się w czasie. Teoretycznie taki wektor może wygenerować każdy program muzyczny (DAW), a proces przetwarzanie dźwięków określa się jako DSP (Cyfrowe Przetwarzanie Sygnałów).
Sugeruje to, że muzyka instrumentalna, która teraz powstaje, może być tworzona bez udziału muzyków oraz bez użycia instrumentów (analogicznie jak muzyka elektroniczna) i bardzo często tak jest. Stworzono wiele wtyczek VST symulujących brzmienie instrumentów akustycznych, poprzez układanie melodii w standardzie MIDI (Musical Instrument Digital Interface). Większość brzmiała sztucznie – syntetycznie, a ich algorytmy niewiele różniły się od tych stosowanych w samplerach VST. Użycie odpowiednio przetrenowanych sieci neuronowych może sprawić, że nie będziemy w stanie odróżnić brzmienia, prawdziwego instrumentu od tego wirtualnego, takie wtyczki coraz częściej stosują udoskonalony model – DDSP (Różnicowe Cyfrowe Przetwarzanie Sygnałów).
Oto kilka nowoczesnych instrumentów VST, które są bardzo często używane w studiach nagraniowych:

Widok wtyczki VST: Addictive Drums 2 do symulacji brzmienie perkusji.
Addictive Drums – nagrywanie perkusji to jedno z najtrudniejszych zadań realizatora dźwięku. Proces ten wymaga użycia wielu mikrofonów i wielu prób – eksperymentów. Ten plugin VST perfekcyjnie symuluje brzmienie różnych zestawów perkusyjnych i nie potrzebuje perkusisty. Twórcy wprowadzili funkcjonalność, którą nazwali „Beat Transformer”. Jest to narzędzie, które umożliwia manipulowanie rytmem i aranżacją partii perkusyjnych w czasie rzeczywistym, za pomocą wytrenowanej sieci neuronowej. Dzięki temu użytkownicy mogą eksperymentować z różnymi wariantami rytmicznymi, a program automatycznie dopasuje je do aktualnie granego tempa i stylu.
Virtual Bassist – firmy UJAM; program pozwala na tworzenie realistycznych partii basowych dla różnych stylów muzycznych. Do generowania dźwięków wykorzystywane są wytrenowane modele głębokich sieci neuronowych, które analizują dane wejściowe, takie jak harmonia i rytm. Na ich podstawie generuje dopasowane do utworu riffy. Posiada wbudowane funkcje improwizacji, w której można wybrać różne style gry, tempo i intensywność, a następnie wspólnie jamować. Jest to przydatne rozwiązanie, w procesie wymyślania melodii.
Firma UJAM oferuje odmiany programu: Virtual Guitarist, Virtual Drummer i Symphonic Elements, które działają w analogiczny sposób i również można je używać jako wirtualnego improwizatora. Ich program Finisher, pozwala zautomatyzować proces postprodukcji muzycznej, czyli masteringu…
Płacić czy nie płacić za automatyzację postprodukcji?
Mastering możemy też zrobić na portalu Soundcloud, płacąc 4.99$ na miesiąc. Z pewnością znajdą się entuzjaści tego sposobu, tak jak znajdują się entuzjaści archaicznej metody cyfrowego-analogowego masterowania (DAC/ADC), poprzez zgranie utworów na szpulową taśmę magnetofonową i z powrotem na formę cyfrę (ma ona swoje plusy). Jednak proces ten można usprawnić, używając wtyczki-equalizera „Neural EQ” i wtyczki-kompresora „Neural Compressor”. W obydwu VST zastosowano sieci neuronowe, wytrenowane na wielu utworach. Pozwala to automatycznie wygenerować oryginalne brzmienie kompozycji w procesie postprodukcji muzycznej.
Przerost formy
W obszarze pluginów VST warto się zastanowić, czy użycie uczenia maszynowego jest konieczne w procesie twórczym do uzyskania pożądanego efektu i czy można ten proces zoptymalizować do wymagań hardwaru. W idealnych warunkach stosowanie VST powinno odbywać się w czasie rzeczywistym, niestety w programach muzycznych DAW nie unikniemy czasu propagacji, który wywołuje latencję. Pluginy VST są tworzone w natywnych językach programowania, stosują układy wewnętrzne przyspieszające ich pracę. Używanie zbyt złożonych algorytmów może tak znacząco zwiększyć latencję, że generowana muzyka będzie musiała być już renderowana (jak w przypadku wirtualnych kompozytorów) i problematyczne będzie zagranie jamu na żywo z wirtualnym improwizatorem.
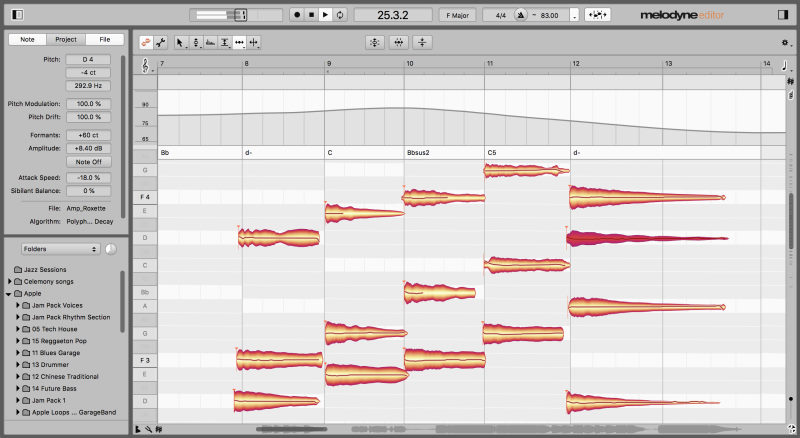
Melodyne – oprogramowanie do edycji dźwięku i korekty melodyki.
Nie każdy proces produkcji muzycznej wymaga pracy w czasie rzeczywistym. Sztuczna inteligencja może zautomatyzować pocięcie np. loopów perkusyjnych, w celu przestawienia kolejności beatu. Często jest to praktykowane w muzyce elektronicznej w gatunku Drum’n’Bass (Stosowane inteligentne VST to: Melodyne, DDSP-VST i prostszy SliceX). W usunięciu wokalu z piosenki, aby stworzyć utwór na karaoke, pomogą nam inteligentne filtry używane w Spleeter i Vocal Remover.

Jeden z pierwszych syntezatorów Moog Modular Systems, wzbogacony o dodatkowe moduły.
Warto wymienić parę przypadków, które całkowicie odrzucają ideę technik cyfrowych podczas produkcji. Gitarzysta Red Hot Chilli Peppers – John Frusciante, do nagrywania swoich solowych płyt używał stereofonicznego magnetofonu ośmiościeżkowego; jest to archaiczne podejście. Producent muzyki elektronicznej Rhys Fulber, w jednym ze swych projektów, używa syntezatorów analogowych Moog z 1964 roku. Jednak ich konstrukcja jest tak udana, że powstało wiele symulacji VST tego instrumentu. Z takim podejściem obaj panowie z pewnością nie narzekają na problem latencji.
Inną ciekawostką jest popularny zespół The Prodigy, który praktycznie w każdym swoim utworze wykorzystał sample z muzyki innych zespołów, przez co może nasunąć się porównanie, że ich twórczość przypomina działanie algorytmu genetycznego. Jest to też kontrargument na zarzuty odtwórczego stosowania bazy danych artystów przez sieci neuronowe, w celu przetwarzania ich – inspiracji zawsze jest niezbędna.
Ograniczenia
Programy muzyczne, stosujące sieci neuronowe mają swoje ograniczenia. Zazwyczaj stosują małe zbiory danych trenujących oraz wymagają dużej złożoności treningu. Badacze zajmujący się uczeniem maszynowym obrazu i języka mierzą swoje zbiory danych na podstawie milionów lub miliardów przykładów, badacze muzyki mają szczęście, jeśli mogą zebrać bazę, kilku tysięcy przykładów dla danego zadania (a gotowe udostępniane dane trenujące mogą nie odpowiadać naszym gustom). Powoduje to często, że używany wirtualny kompozytor lub instrument, ma swój osobliwy styl i brzmienie.
Czego możemy spodziewać się w przyszłości
Analizując nowe rozwiązania w branży muzycznej, można dojść do wniosku, że rynek producentów muzyki jest mocno nasycony, oferta jest bardzo różnorodna. Jeśli oczekujemy na nowości w branży, można wskazać połączenie DDSP (różnicowego cyfrowe przetwarzanie sygnału) z symulacją modelu fizycznego instrumentu oraz nowe wtyczki VST do generacji i modyfikacji sygnału, oparte o model DDSP wspierane przez hardware.
Przykładem może być gitara elektryczna. Istnieją bardzo dobre efekty VST, które przesterowują analogowy sygnał gitary (HELIX, Neural DSP – obalają mit lepszego brzmienia wzmacniaczy lampowych). Jednak nie łatwo jest wygenerować cyfrowo substytut wspomnianego sygnału analogowego, który bardzo zależy od instrumentu. W rozwiązaniu tego problemu może pomóc nowy standard DDSP-MIDI, który jest rozwinięciem standardu MIDI z dokładniejszą syntezę brzmienia.
Należy dodać, że muzyka odtwarzana jest przeważnie w niezmiennej technice stereofonicznej, która powstała w 1931 roku, i jeśli chcielibyśmy tutaj wymyślić coś nowego, to nie będzie łatwo. Istnieją już dedykowane sieci neuronowe do up-mixingu, czyli przetwarzania sygnału audio o niższej liczbie kanałów na sygnał o wyższej liczbie kanałów, czyli z sygnału stereo na sygnał 5.1 lub 7.1. Przykładem takiej sieci neuronowej może być np. Deep Neural Network for Spatial Audio Upmixing (DNN-SAU).
Stosowanie najnowszych technologii raczej nie zapewni sukcesu, ale może dać wiele inspiracji i urozmaicić proces twórczy. Jednak Jeśli rynek sztuki cyfrowej zostanie wypełniony symulowanymi tworami, być może bardziej doceniamy rękodzieło i częściej zaczniemy słuchać muzyki “na żywo”.
Na koniec, nawiązując do wątku „Drowned In The Sun”, posłuchajmy zespołu Nirvana w wersji stworzonej przez AI oraz „Białej Chorągiewki” rzeszowskiego zespołu 1984. I zastanówmy się czy zespół Nirvana, gdyby nadal istniał, czerpałby inspirację z rzeszowskich zespołów zimnofalowych?
„Drowned In The Sun” – 2020r.
1984 – “Biała Chorągiewka” – 1991 r.
