
Asystent badawczo-dydaktyczny w Kolegium Informatyki Stosowanej, w Katedrze Sztucznej Inteligencji. Magister inżynier informatyki o specjalności Inżynieria Inteligentnych Systemów Informatycznych. Jego zainteresowania naukowe skupiają się wokół systemów podejmowania decyzji, rozpoznawania i sterowania, szczególnie tych wykorzystujących uczenie maszynowe, z naciskiem na wykorzystanie metod nie-głębokich. Interesuje się także analizą złożonych typów danych, takich jak szeregi czasowe, obrazy i filmy pod kątem uczenia maszynowego, inżynierią cech oraz rozwiązaniami IoT.
Jak komputer uczy się sam? Wprowadzenie do uczenia maszynowego
W ostatnim czasie trudno było nie natknąć się na tematy związane ze „sztuczną inteligencją”. Jest to bardzo gorący temat, na który można natknąć się na każdym kroku, w przestrzeni internetowej i nie tylko – od wygenerowanych treści, takich jak obrazy, filmy, dźwięki, czy teksty i narzędzi, do ich generowania, przez reklamy sprzętów codziennego użytku sygnowanych skrótowcem „AI”, aż po dywagacje, czy sztuczna inteligencja zabierze ludziom pracę, czy może w ogóle przejmie władzę nad światem i unicestwi ludzkość. Ta eksplozja popularności terminu sztucznej inteligencji wynika z przełomowych odkryć dokonanych w tej kwestii w ostatnich latach (dla zainteresowanych: mowa o czymś takim jak „architektura Transformer”), natomiast nie jest to zagadnienie, które pojawiło się znikąd, nagle i dopiero teraz. Sztuczna inteligencja funkcjonuje już od dziesiątek lat i choć może przez większość tego czasu z jej zastosowań nie wynikały tak widowiskowe efekty, jakie możemy obserwować dzisiaj, tak jednak AI, jako program komputerowy, którego zadaniem jest wykonywanie zadań na ogół wymagających ludzkiej inteligencji, w dużej mierze opartych na wnioskowaniu i podejmowaniu decyzji w oparciu o jakieś informacje, jest z nami od dawna. Pod sztuczną inteligencję można nawet podpiąć proste systemy sterowania oparte na zasadzie „Jeżeli X, to zrób Y”, które programowo można przedstawić w postaci szeregu instrukcji warunkowych i z którymi spotkał się niemal każdy, kto zagrał w jakąkolwiek grę komputerową dla jednego gracza, gdzie były postacie sterowane przez komputer. Najprostsze systemy tego typu jako źródło informacji, czyli tego jak w danej sytuacji mają zadziałać, traktują tak zwaną wiedzę ekspercką, czyli innymi słowy, działania takiego systemu są z góry zdefiniowane przez człowieka. Dla prostszych zastosowań takie podejście wystarcza, natomiast wraz ze stopniem skomplikowania problemu robi się coraz większy kłopot, bo taką ekspercką wiedzę ciężko zaimplementować komputerowo, a też nie zawsze taka ekspercka wiedza w ogóle jest dostępna. Do wdrażania rozwiązań sztucznej inteligencji dla bardziej skomplikowanych problemów, gdzie sama wiedza ekspercka nie wystarcza, wykorzystuje się podejście zwane uczeniem maszynowym.
Uczenie maszynowe to gałąź sztucznej inteligencji, która nie traktuje jako źródło wiedzy, na podstawie której podejmuje działania, z góry określonej wiedzy eksperckiej, a czerpie wiedzę z danych. Podejście to najczęściej polega na tym, że dla zbioru danych, na który składa się jakaś liczba obserwacji – pojedynczych przypadków rozpatrywanego problemu budujemy tak zwany model, który posiadając wiedzę z jakichś danych jest w stanie przewidywać nowe, nieznane mu wcześniej przypadki. Przykładowo, gdyby rozpatrywać system medyczny, którego zadaniem jest rozpoznawanie, czy u danego pacjenta występuje jakaś choroba, to zbiór danych do takiego problemu powinien składać się z historycznych informacji o pacjentach dokładniej przebadanych w kontekście takiej choroby, gdzie pojedynczą obserwacją byłby w takim przypadku jeden pacjent. Model uczenia maszynowego w tym przypadku, na podstawie podanych mu danych, nazywanych danymi uczącymi, nauczy się zależności potrzebnych do rozróżniania pacjentów zdrowych od chorych. Trzeba mieć jednak na uwadze, że jeśli zbiór danych był skonstruowany w określony sposób, czyli na przykład w formie tabeli, w której kolumny pokazywałyby wyniki określonych badań, czy inne parametry zdrowotne pacjenta, to z wykorzystaniem takiego modelu możemy dokonać predykcji – rozpoznania, czy pacjent jest chory, jedynie na podstawie nowych danych, które będą skonstruowane w taki sam sposób, tj. nowi pacjenci będą opisani tymi samymi cechami. Tak to przynajmniej wygląda dla najprostszej postaci danych, czyli takich, które da się przedstawić w formie tabeli, czyli formie, która z definicji ma ściśle określoną strukturę. Przykład takiej bardzo prostej tabeli przedstawia poniższy rysunek 1.
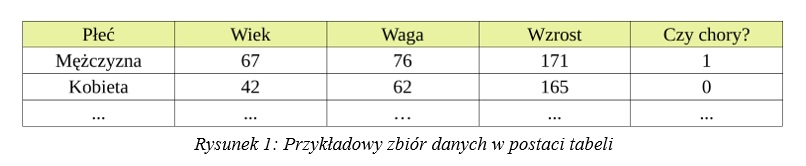
W tabeli tej mamy kilka przykładowych wierszy z informacjami o pacjentach – obserwacji, opisanych pięcioma cechami: płcią, wiekiem, wagą, wzrostem i kolumną określającą, czy u danego pacjenta stwierdzono chorobę, gdzie 1 oznacza chorobę, a 0 oznacza, że pacjent był zdrowy. Ta ostatnia cecha jest w tym przypadku naszą szukaną, tą, którą chcemy modelem uczenia maszynowego przewidywać. Taka cecha nazywa się atrybutem decyzyjnym i w zależności od tego, jakie przyjmuje on wartości i tego czego oczekujemy od modelu, można mówić o dwóch największych kategoriach uczenia maszynowego – klasyfikacji oraz regresji. Pierwsza z nich określa problem rozpoznawania, tj. nadania nowym obserwacjom jakiejś etykiety, czy inaczej klasy. Przykładem klasyfikacji jest podany przykład wykrywania choroby, ale w problemie klasyfikacji może występować więcej możliwości niż jedynie rozpoznawanie problemu z kategorii tak/nie. Atrybut decyzyjny dla klasyfikacji przyjmuje jedną z grupy przyjętych wartości i także tylko takie będzie w stanie potem nadać nowym obserwacjom, tj. przykładowo w systemie, w którym rozróżnialibyśmy koty od psów, jeśli na wejście nauczonego modelu podamy dane świnki morskiej, to będzie ona i tak zakwalifikowana jako pies lub kot, a przynajmniej tak by to działało w najprostszych modelach, które nie sprawdzają, czy nowe dane nie odbiegają przypadkiem za bardzo od tego co znają. Regresja natomiast to problem przewidywania ciągłej wartości, innymi słowy można ją nazwać procesem szukania funkcji jak najlepiej dopasowującej się do znanych danych, tak aby można było rzetelnie przewidywać liczbowe wartości dla nieznanych obserwacji. Przykładem problemu regresji jest przewidywanie różnych kwot pieniężnych, chociażby w kontekście zagadnień takich jak zyski, straty, czy koszty. Problemem regresji można również nazwać przewidywanie jakiegoś prawdopodobieństwa i przykładowo w dużym uproszczeniu można powiedzieć, że popularne dziś duże modele językowe, wykorzystywane przez narzędzia takie jak ChatGPT realizują problem regresji wyznaczając na podstawie prawdopodobieństw, jakie słowa powinny pojawić się jako następne w zdaniu.
Klasyfikacja i regresja to kategorie, które stanowią razem uczenie maszynowe nadzorowane. Dużą kategorią uczenia maszynowego jest jednak także tak zwane uczenie nienadzorowane, gdzie pracuje się na danych, w których obserwacje nie są opisane i polega ono na wyszukiwaniu wzorców w samych danych, na przykład poprzez ich podział na grupy, co znajduje zastosowanie w analizie danych. Inną gałęzią uczenia maszynowego, różniącą się od klasycznego podejścia jest tak zwane uczenie ze wzmocnieniem, które nie wykorzystuje zbioru danych, ale jako informacji do uczenia używa wiedzy pochodzącej od otoczenia – jest to kategoria uczenia maszynowego służąca do nauczenia tak zwanego agenta poruszania się i działania w określonym środowisku, gdzie chyba najbardziej obrazowym przykładem zastosowania są autonomiczne roboty, czy komputerowo sterowane postacie w grach komputerowych.
Opowiedzieliśmy sobie czym to uczenie maszynowe jest, ale nie poruszyliśmy jeszcze jednego bardzo ważnego tematu z artykułu, a mianowicie tego – jak to w ogóle działa i jak ten komputer się „sam” uczy. Zacznijmy więc od tego, że nie jest to żadna magia, jak może się wydawać patrząc na współczesne twory AI, a zwykła matematyka. Większość algorytmów uczenia maszynowego pracuje na danych w postaci liczbowej (informacje nie-liczbowe, takie jak płeć należy najpierw przekonwertować na liczbę, np. kodując mężczyzn jako 0, a kobiety jako 1) i swoje zdolności poznawcze opiera na zależności pomiędzy tymi liczbami. Różne metody podchodzą do tego zagadnienia w różny sposób. Jedne analizują ważność poszczególnych cech, inne pracują na podobieństwie obserwacji między sobą, a jeszcze inne mogą mieć jakieś swoje unikalne sposoby na uczenie się. Zagłębienie się w świat algorytmów uczenia maszynowego i poznawanie ich działania od środka jest bardzo interesujące i potrafi wzbudzać podziw nad tym, jak niektóre kwestie zostały sprytnie rozwiązane. Na potrzeby tego artykułu skupimy się natomiast na jednej z prostszych metod, którą można wykorzystać w analizie danych, która jest prosta do zrozumienia, przedstawienia, implementacji, a także w tym wszystkim skuteczna i powszechnie wykorzystywana, a mowa tutaj o algorytmie grupowania nazywanym jako metoda k-średnich.
Metoda k-średnich to metoda uczenia nienadzorowanego, która grupuje zbiór danych do z góry określonej liczby grup, inaczej nazywanych klastrami, którą w algorytmie oznacza się jako k. Algorytm ten grupuje obserwacje na podstawie odległości między nimi, więc w tym momencie warto się zatrzymać i powiedzieć czym jest ta odległość. Tak naprawdę w tym przypadku słowo „odległość” rozumie się tak samo jak rozumiemy to słowo dosłownie, jako dystans między dwoma punktami, czy jeszcze ogólniej jako miarę tego jak blisko (lub daleko) są względem siebie dwa punkty. W klasycznym układzie współrzędnych, gdzie mamy dwie osie – X i Y i możemy łatwo wizualnie określić odległość między dwoma punktami, a także ją bardzo prosto policzyć, co często robiło się w zadaniach na matematyce w szkole, chociażby w kontekście Twierdzenia Pitagorasa, bo obliczanie długości przeciwprostokątnej to też nic innego jak wyznaczanie odległości pomiędzy dwoma punktami należącymi do trójkąta. Rysunek 2 pokazuje dokładnie o co chodzi, jeśli mówimy o odległości między dwoma punktami w dwuwymiarowym układzie współrzędnych.
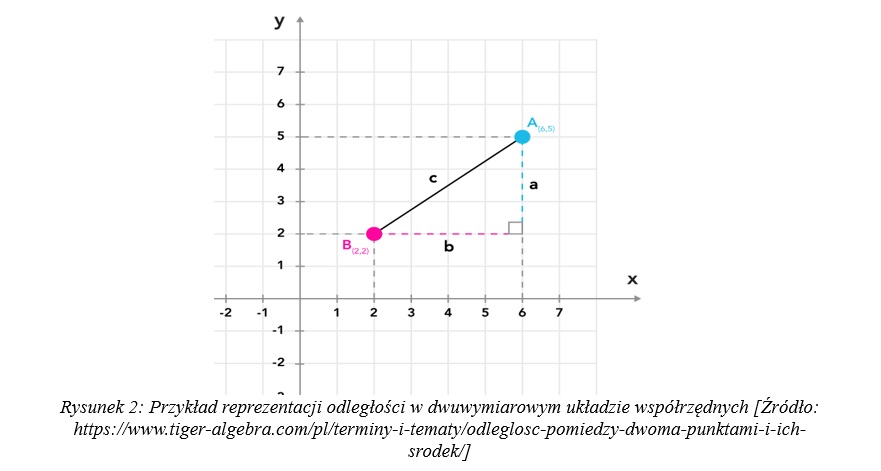
Jeśli na nasz zbiór danych składałyby się jedynie dwie cechy, to obserwacje ze zbioru danych możemy zaznaczyć na takim układzie, odległość między obserwacjami określać mogłaby linia c tak jak na powyższym rysunku, a jej długość można by policzyć z Twierdzenia Pitagorasa. W przypadku kiedy cech w zbiorze byłoby więcej, to w zasadzie sprawa jest identyczna, tylko trudniejsza do wyobrażenia. W układzie współrzędnych, gdzie dla każdej cechy mamy osobną oś wciąż odległością między punktami byłaby linia prosta łącząca te dwa punkty, a jej długość można obliczyć z zależności podobnej do Twierdzenia Pitagorasa uwzględniającej więcej wymiarów. Ogólnie miarę odległości, która określa długość najkrótszej linii łączącej dwa punkty nazywa się odległością euklidesową.
Algorytm k-średnich przydziela obserwacje do grup na podstawie odległości w taki sposób, że w układzie współrzędnych dla rozpatrywanego problemu wyznacza się punkty, takie sztuczne, wirtualne obserwacje pełniące role centroidów, czyli środków grup. Przydział nowej obserwacji do grupy odbywa się poprzez wyliczenie jej odległości od każdego ze środków i przydzieloną grupą będzie ta, do której jej najbliżej. Centroidy są elementem, którego metoda się uczy w iteracyjnym procesie uczenia. Na początku działania metody ich współrzędne, czyli wartości cech tych „wirtualnych” obserwacji wyznacza się losowo. Potem zadaną liczbą kroków powtarza się operację przesuwania tych centrów. Odbywa się to poprzez wyznaczenie dla każdej obserwacji ze zbioru danych, którym dysponujemy, odległości do każdego z centrów i wybór tego, do którego im najbliżej. Współrzędne nowych centrów w każdym kroku to średnie wartości współrzędnych obserwacji, które zostały przypisane do grupy, które dane centrum reprezentuje. Przesuwanie centroidów można zakończyć wcześniej niż wskazuje na to zadana liczba kroków, na przykład w oparciu o to, czy w kolejnych krokach centra w ogóle się przesuwają, lub czy te przesunięcia są jakkolwiek znaczące. Rysunek 3 pokazuje dwie iteracje działania algorytmu.
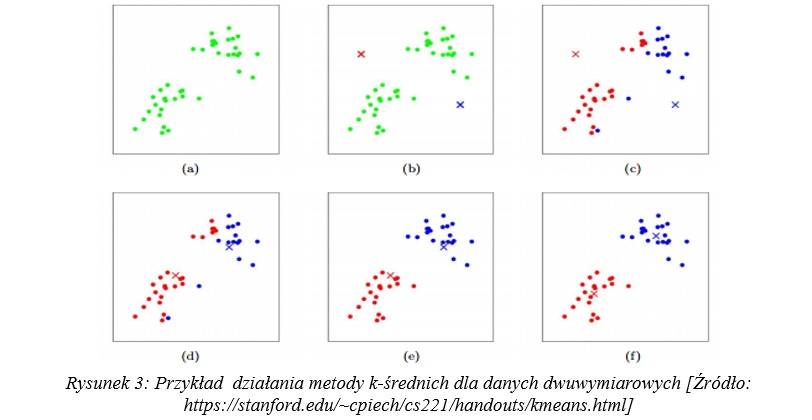
Na powyższym rysunku, podpunkt (a) ukazuje początkowy, niepogrupowany zbiór danych. W podpunkcie (b) zainicjalizowano losowo dwa środki grup i oznaczono je krzyżykami w różnych kolorach. W podpunkcie (c) wykonano pierwszy przydział danych do grup, a w podpunkcie (d) przesunięto centroidy w stronę średnich wartości cech w poszczególnych grupach. Analogicznie do podpunktów (c) i (d) w podpunktach (e) i (f) odbywa się druga iteracja metody i po tej iteracji widać, że dwie wyznaczone grupy są od siebie widocznie odseparowane. Metoda k-średnich to prosta i powszechnie wykorzystywana metoda grupowania, a samo grupowanie jest przydatne w analizie dużych zbiorów danych w kontekście wyszukiwania podobieństw – na przykład w przypadku analizy danych o klientach jakiegoś sklepu możemy sklasyfikować ich na grupy w celu pokazywania im, a także nowym, podobnym do nich klientom, bardziej trafnych reklam.
Wszystkie pokazane i omówione w tym artykule przykłady opierały się na bardzo prostych danych w postaci tabeli, natomiast uczenie maszynowe to znacznie więcej niż tylko proste tabelki – co zresztą widać po sukcesie modeli językowych w postaci narzędzi typu ChatGPT, czy modeli wizyjnych pracujących na obrazach, bo one to też nic innego jak uczenie maszynowe, tylko zrealizowane na znacznie bardziej złożonych danych niż taka dydaktyczna reprezentacja tabelaryczna. Sama idea działania w przypadku tych bardziej skomplikowanych zastosowań pozostaje jednak niezmienna i wciąż w matematyczny sposób uczą się zależności między danymi. Skomplikowane problemy, takie jak praca z tekstem czy obrazami, to na ogół domena poddziedziny uczenia maszynowego, jaką jest uczenie głębokie, które tym różni się od uczenia maszynowego, że wykorzystywanymi są tam sieci neuronowe, które zmiennych parametrów w procesie uczenia mają dużo więcej niż chociażby taka prosta metoda k-średnich i liczy się je nawet w milionach. Modele uczenia głębokiego w dużej mierze działają jak czarna skrzynka, która zwraca wynik, ale w zasadzie nie da się stwierdzić na jakiej podstawie jest on taki, a nie inny, bo sama struktura matematyczna modelu jest zbyt złożona do przeanalizowania jej ludzkim okiem.
Podsumowując, uczenie maszynowe i ogólnie sztuczna inteligencja to nie jest magia i nikt, przynajmniej na razie, nie tchnął w komputer życia niczym mitologiczny Prometeusz, a jest to tak naprawdę zwykła matematyka i algorytmika. Ostatnie lata przyniosły znaczący rozwój w tej dziedzinie, za którym idą ogromne pieniądze, jakimi teraz się obraca w sferze AI, które tym bardziej mają wspomóc rozwój technologii opartych o uczenie maszynowe. Nawet jeśli te najpoważniejsze zastosowania ze względu na ograniczenia w dostępności danych i mocy obliczeniowej pewnie na długo pozostaną domeną największych tego świata, tak nigdy też nie będzie brakowało zastosowań dla prostych, bardziej przyziemnych i lokalnych metod uczenia maszynowego, które zdecydowanie warto zgłębiać.
Niniejszy artykuł jest powiązany z treściami kształcenia realizowanymi na przedmiocie „Uczenie maszynowe dla Big Data” na kierunku studiów drugiego stopnia „Analityka biznesowa i Big Data”.
